IA et vecteurs, quand vos données prennent tout leur sens
Chat-GPT, Bard, Mistral et toute autre intelligence artificielle sont-elles capables de comprendre le sens derrière chaque mot ? Afin de répondre à cette question, mettons en lumière les vecteurs et bases de données vectorielles, qui permettent à l’intelligence artificielle de donner vie à des modèles capables d’interpréter et de comprendre les subtilités des informations qui lui sont fournies. Découvrez comment les modèles d'intelligence artificielle transforment des textes en vecteurs puissants, ouvrant ainsi la porte à des possibilités d'analyse sémantique.

Avant même de plonger dans le sujet, si vous n’êtes pas familier avec les termes : token, modèle, LLM, je vous conseille vivement de consulter notre article accessible à tous : Décryptage des modèles d'Intelligence Artificielle.
Pour répondre à la question “Comment une machine peut-elle extraire le contexte d’un texte ?”, il faut tout d’abord définir ce qu’est la sémantique, un vecteur, puis enfin ce qu’est une base de données vectorielles.
Qu’est-ce que la sémantique ?
Dans le contexte de l’IA (intelligence artificielle), la sémantique concerne la manière dont les modèles LLM interprètent et “comprennent” les informations. Si nous prenons l’exemple du terme "Lettre" : celui-ci peut désigner soit un courrier, ou bien le caractère d’écriture. La sémantique vise à éclaircir ces subtilités afin de permettre au modèle de traiter les données avec efficacité.

Qu’est-ce qu’un vecteur ?
Comme l’explique si bien Cloudflare : “En mathématiques, un vecteur est une combinaison de nombres qui définit un point dans un espace dimensionnel. En langage plus pratique, un vecteur est une liste de nombres, par exemple 0.15, 1.1, 1.40, -0.2, ..., 0.14, -0.13. Chaque nombre indique la position de l'objet le long d'une dimension donnée”. Une base de données vectorielle stocke entre autres des informations sous cette forme.
Une base de données vectorielle constitue un ensemble organisé de données représentées sous forme de tableau (vecteurs multidimensionnels), utilisée pour stocker et manipuler des informations provenant d'images, de textes, de sons ou d'autres données numériques, offrant ainsi une structure pour l'analyse des données.
| Série télévisée | Genre | Année de début | Durée des épisodes | Saisons (jusqu'en 2023) | Épisodes (jusqu'en 2023) |
|---|---|---|---|---|---|
| Seinfeld | Sitcom | 1989 | 22-24 | 9 | 180 |
| Mercredi | Horreur | 2022 | 46-57 | 1 | 8 |
Dans le tableau ci-dessus, on voit 2 séries, Seinfeld et Mercredi, on pourrait les convertir en vecteurs de cette façon :
- Seinfeld : [’Sitcom’, 1989, 22-24, 9, 180]
- Mercredi : [’Horreur’, 2022, 46-57, 1, 8]
Chaque colonne serait exprimée comme une dimension, créant ainsi deux vecteurs de 5 dimensions.
Cependant, la colonne Genre, qui contient des données catégorielles telles que 'Sitcom' ou 'Horreur', ne peut pas être directement représentée par un simple nombre dans un vecteur numérique. Pourtant elle se doit d’être une valeur numérique, mais il n’y a pas d'étalonnage possible avec des genres de série. C’est-à-dire qu’on ne peut pas ordonner les genres (de façon linéaire).
Pour intégrer ces informations dans un vecteur qui peut être traité par un modèle d’IA, il faut convertir ces catégories en données numériques. Plusieurs techniques sont possibles. La plus simple étant de transformer la colonne Genre en plusieurs colonnes binaires où chaque colonne correspond à une catégorie de genre possible, avec une valeur de 1 pour indiquer la présence de ce genre et 0 pour son absence. Cette méthode s'appelle le One-Hot Encoding. Une fois cette conversion effectuée, les vecteurs prennent la forme suivante :
- Seinfeld : [1989, 22-24, 9, 180, 1, 0, 0, 0, 0], où 1 est pour Sitcom et les 0 pour les autres genres.
- Mercredi : [2022, 46-57, 1, 8, 0, 1, 0, 0, 0], où 1 est pour Horreur et les 0 pour les autres genres.
Cette méthode permet de maintenir l'intégrité des informations originales tout en les rendant exploitables pour des analyses complexes, telles que la comparaison de similarités, la classification, ou la recommandation basée sur les préférences des utilisateurs
Embedding : la transformation des données
L’embedding est une méthode de transformations de données provenant d'images, de textes, de sons, de données utilisateur, ou de tout autre type d’information, en vecteurs numériques. Cela revient à traduire le langage humain en une langue que les machines peuvent interpréter, capturant ainsi les nuances sémantiques ou contextuelles des éléments traités.
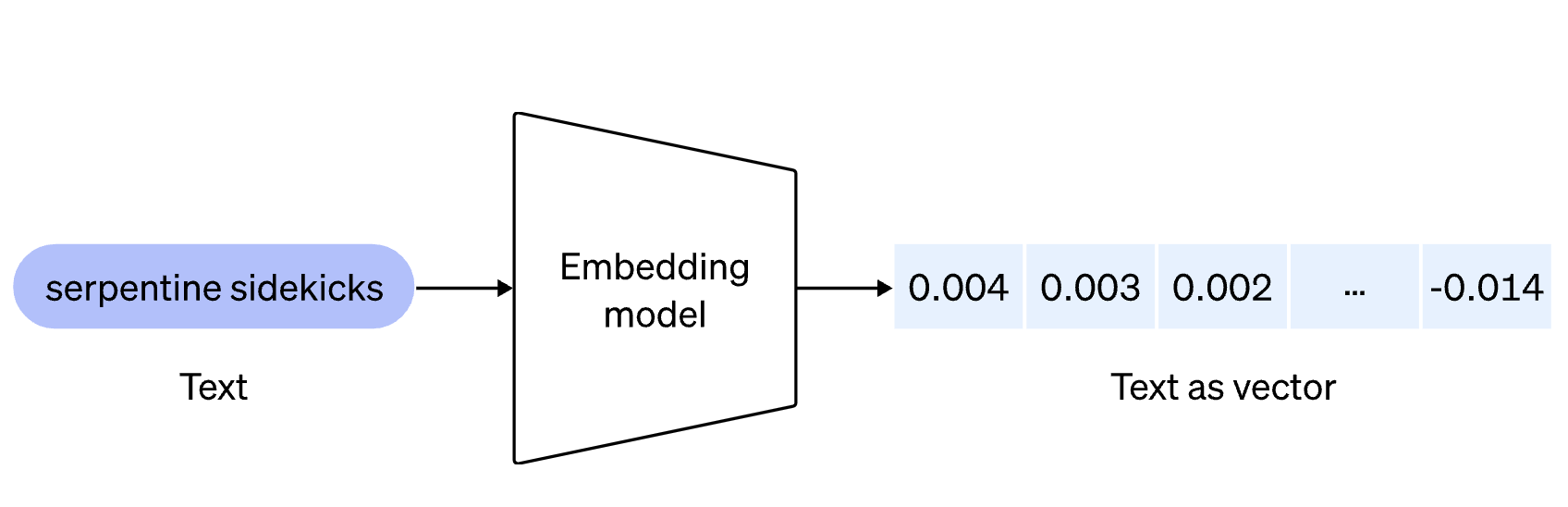
Pourquoi les vecteurs retournés par le modèle d’embedding sont des nombres à virgules… parfois positifs, d’autres négatifs, sans aucun sens, alors que dans notre exemple avec les séries, les nombres sont simplement des entiers positifs avec un sens pour chaque élément ?
Les modèles fonctionnent avec des données qui sont pondérées et normalisées pour capturer des relations complexes et des différences subtiles dans les données. De plus, les vecteurs à virgule flottante permettent une précision accrue dans ces calculs, et les valeurs négatives peuvent représenter l'opposition d'une certaine dimension par rapport à un point de référence ou une moyenne.
L'embedding permet de convertir des informations en formats numériques interprétables par les machines, offrant ainsi des possibilités étendues d'analyse et d'utilisation des données. Prenons le mot “pomme”, l’embedding va le convertir en une série de nombres qui capturent les nuances sémantiques du terme. C’est cette série de nombres que nous appelons vecteur. Les vecteurs peuvent ensuite être utilisés pour des recherches de similitudes, des analyses contextuelles, l'IA générative, etc.
Des mots sémantiquement similaires auront des vecteurs proches les uns des autres dans l'espace vectoriel.
Pour reprendre l’exemple du mot “Lettre”, dans le contexte d’un document, il n’aura pas le même vecteur que le mot “Lettre” qui représente un caractère d’écriture. Ou encore les mots pomme, apple, banane et Google, seront aussi proche dans un espace vectoriel, car ils ont un sens qui les relit.
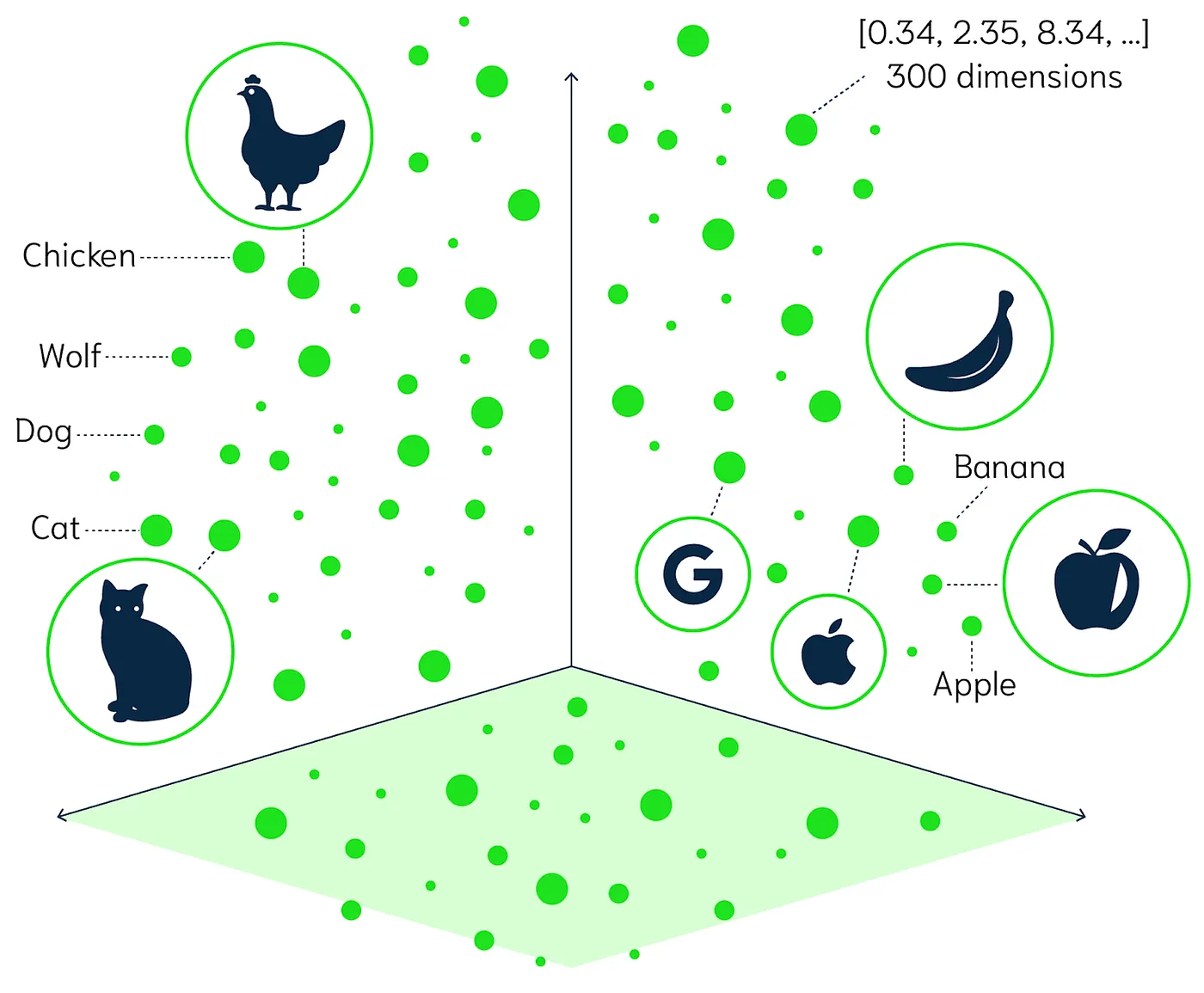
L’illustration ci-dessus schématise des vecteurs sur un plan à 3 dimensions. Cependant, ces vecteurs peuvent s'étendre sur plusieurs centaines de dimensions distinctes. Oui, car comme nous avons vu, chaque colonne du tableau représente une dimension. Chaque mot, token ou phrase peut être converti en un vecteur de plusieurs centaines de dimensions. Le nombre de dimensions dépend du modèle d’embedding choisi.
Ces vecteurs sont essentiellement des points dans un espace multidimensionnel, où chaque dimension agit comme un poids mesurant l'importance, comme évoqué dans notre précédent article sur les modèles LLM. Par exemple, dans l'expression "Atipik va sauver le monde" = [0.34, -1.02, 0.34, 1.2, ..., 1.14, -0.03], chaque nombre dans le vecteur représente un aspect sémantique en plusieurs dimensions.
Pour expliquer de manière (presque) simple : chaque vecteur capture différentes caractéristiques du sens d'un mot ou d'une phrase. Ces vecteurs coexistent dans un espace avec de nombreuses dimensions, où chaque dimension contribue à définir le sens et l'utilisation des mots ou des phrases de manière compréhensible.
Les bases de données vectorielles, c’est (pas) magique.
Maintenant que nous avons des vecteurs, on peut les utiliser entre eux ! Des bases de données optimisées existent pour des opérations telles que la recherche de similarité, comme Pinecone, Weaviate, Zilliz, Milvus, Qdrant.
Résumé d’une recherche à travers une base de données vectorielles
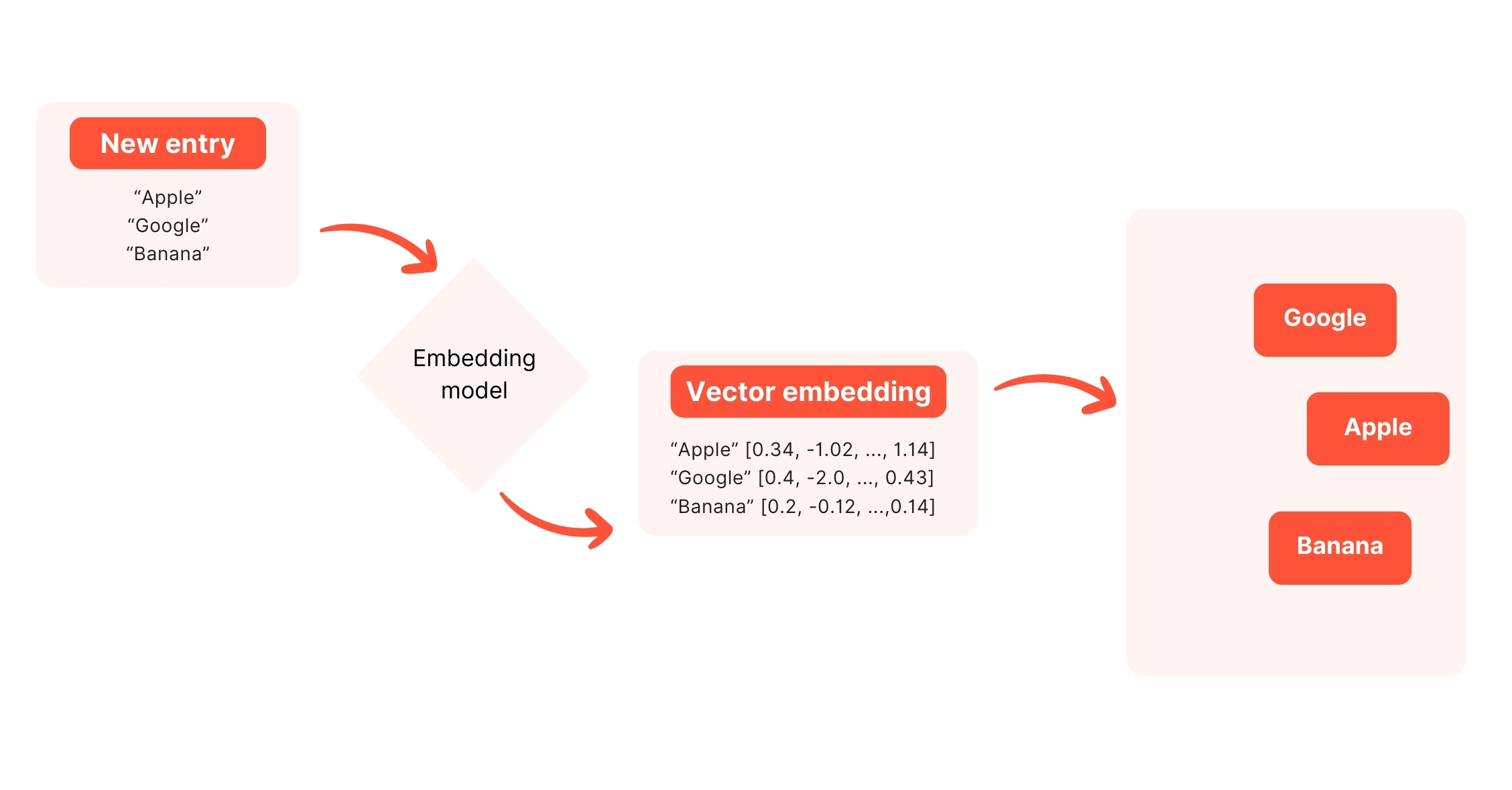
Sur ce schéma, on voit l’ajout dans la base de données. Le processus implique la transformation des données (Apple, Banana, Google) en vecteurs à l'aide d'un modèle d'embedding (Embedding Model) comme french_semantic vu plus haut.
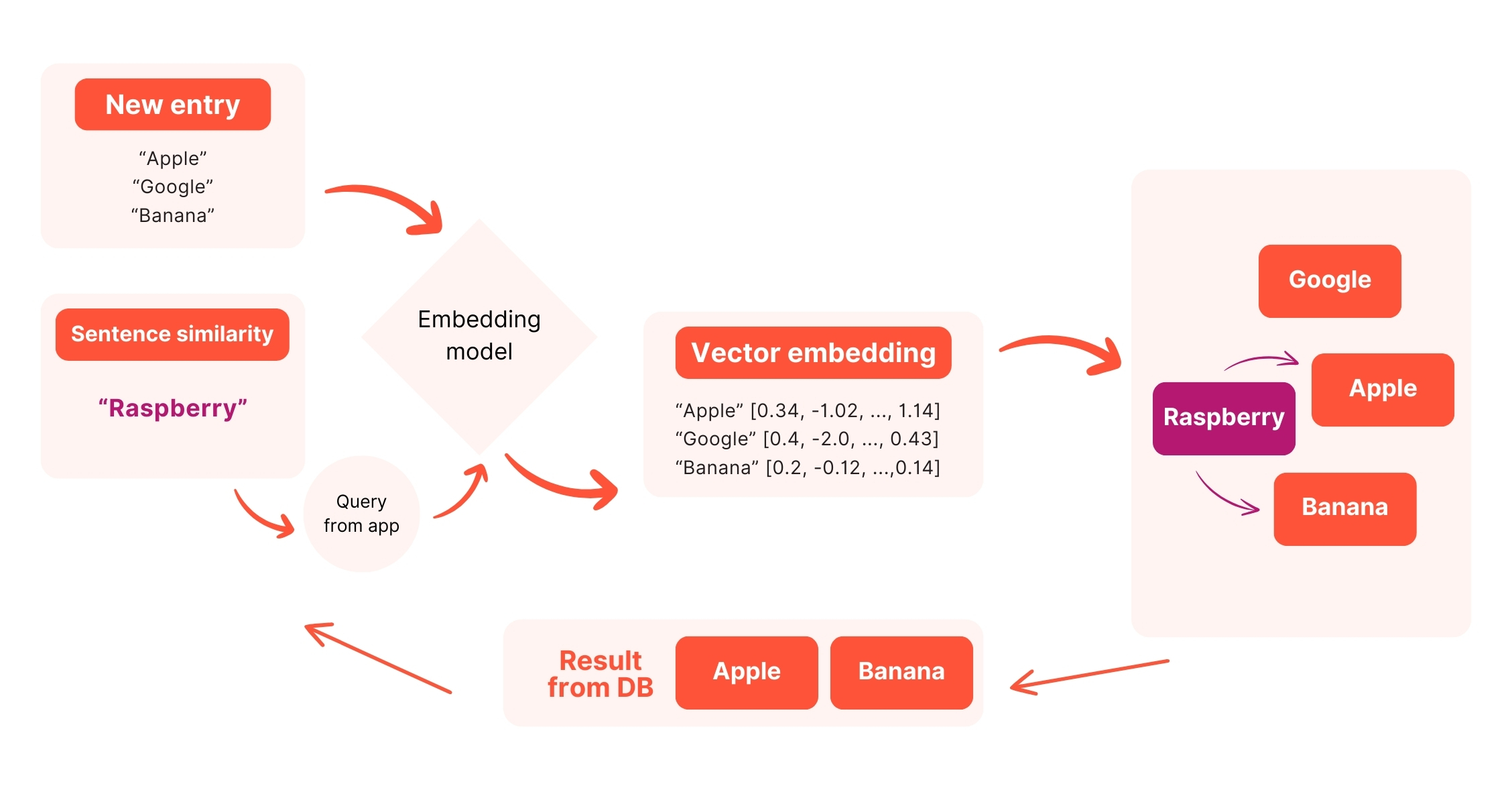
Sur ce schéma on voit la recherche (Query from App) depuis une application. Le processus implique aussi la transformation des données (Rasberry) en vecteurs à l'aide d'un modèle d'embedding. Les vecteurs précédemment insérés sont exploités dans une base de données vectorielle, à travers une recherche de similarités. Les données correspondantes (celles avec les plus de similitudes) sont identifiées via les vecteurs et renvoyées à l'application (Query result).
Mise en pratique d’une recherche à travers une base de données vectorielles
Comme vu plus haut, les données (mot, token, phrase) sont converties en vecteurs. Ils sont ensuite ajoutés à la base de données avec leur texte respectif. Par exemple :
{
'text': 'Il a battu l\'électricien en le mettant à terre',
'vector': [0.34, -1.02, 0.34, 1.2, ..., 1.14, -0.03]
}Indexation : Les vecteurs ajoutés en base sont indexés dans la base de données. L'indexation est une optimisation, pour permettre des recherches rapides. Grâce à l'index vectoriel, nous pouvons interroger efficacement plusieurs vecteurs similaires au vecteur cible.
Recherche : Pour notre exemple, si nous cherchons les textes qui ont le plus de similitudes avec la phrase “Il a fait une prise de judo”. On converti la phrase cible “Il a fait une prise de judo” en vecteur, puis on créer une requête vers la base de données. La base de données effectue ensuite une recherche pour trouver les vecteurs les plus similaires à celui de la cible.
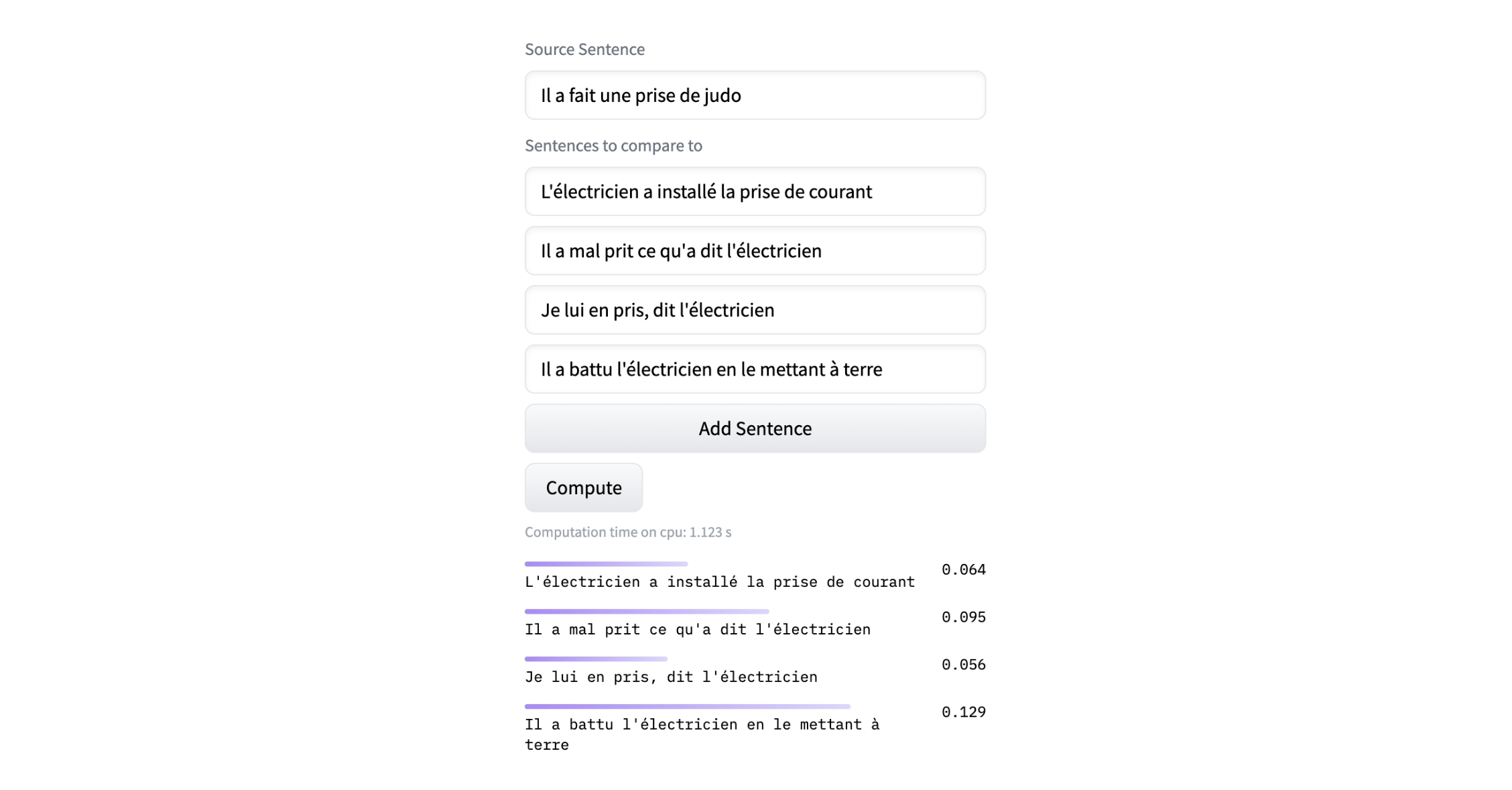
Les résultats sont accompagnés de leur texte, ainsi que le score de similitude sémantique. On peut voir que même sans le mot “prise”, la phrase “Il a battu l’électricien en le mettant à terre” à un meilleur score, car les deux phrases ont une sémantique similaire. De la magie ? Pas vraiment. La similarité est souvent mesurée à l'aide de distances mathématiques, comme la distance euclidienne ou la similarité cosinus. Il existe des milliers d’autres modèles avec leur interface de test sur hugging face.
Pourquoi ne pas utiliser une base de données comme MySQL ?
Les principales raisons pour lesquelles MySQL ne peut pas remplacer ces bases de données spécialisées sont :
- Structure de données : MySQL est conçu autour de tables avec des relations fixes, alors que les bases de données vectorielles gèrent des données sous forme de vecteurs, souvent dans un espace multidimensionnel.
- Recherche par similarité : les bases de données comme Pinecone et Milvus offrent des fonctionnalités de recherche par similarité qui permettent de trouver des vecteurs proches d'un vecteur de requête, ce qui est essentiel pour des applications comme les systèmes de recommandation ou la détection de fraude.
- Scalabilité et performance : ces systèmes sont construits pour gérer de très grands ensembles de données et pour offrir des temps de réponse rapides pour les requêtes complexes, ce qui n'est pas le cas de MySQL.
- Indexation : ces technologies utilisent des techniques d'indexation avancées adaptées aux recherches dans des espaces de haute dimension, ce qui n'est pas le cas de MySQL.

K-Means : grouper par sémantique. Les usages pratiques pour tous.
Admettons la chose suivante : nous avons un grand nombre d’objets, phrases, images, sons ou autre, et nous voudrions les classer par groupe. Par exemple : je reviens de vacances, j’ai 1000 mails à traiter, j’aimerais en faire 5 groupes triés par genre afin de pourvoir les gérer par priorité. C’est la que K-Means entre en jeu.
Comment fonctionne l'algorithme K-Means ?
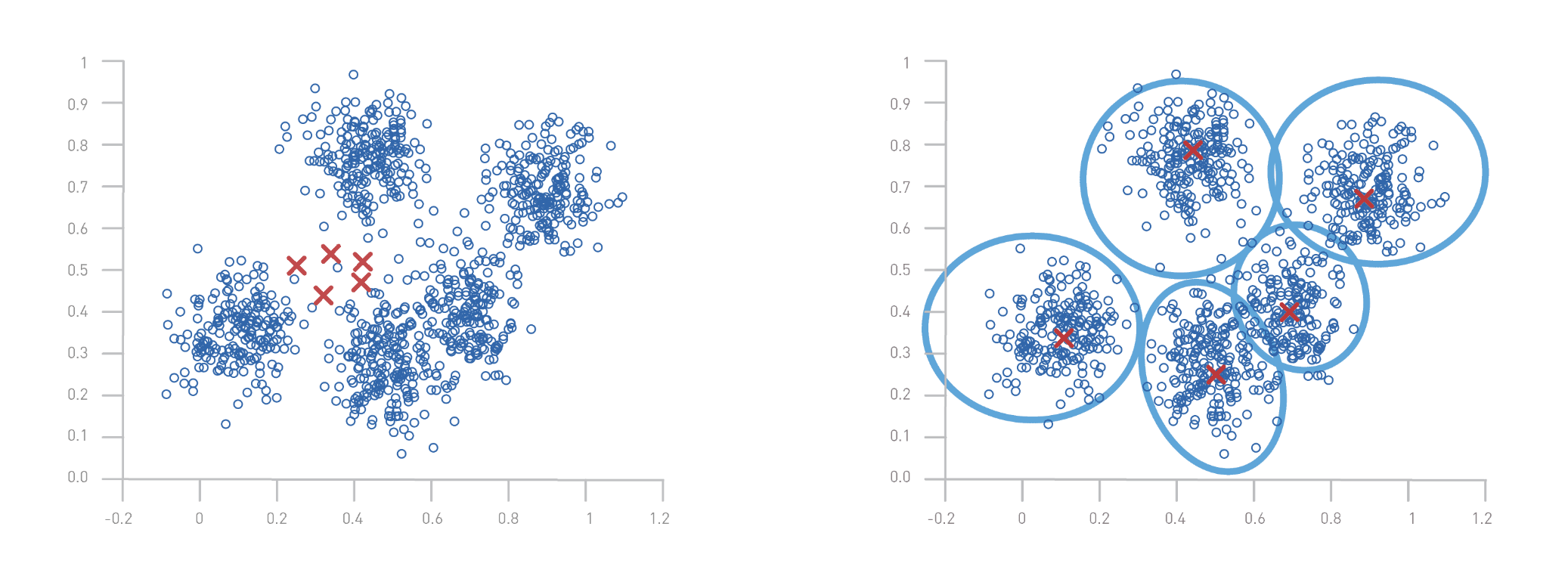
- Choix du nombre de groupes : La première étape consiste à définir le nombre de groupes, ou "clusters", que l’on souhaite créer. Dans notre exemple, nous avons choisi 5 groupes.
- Initialisation des centroïdes : K-Means commence par initialiser aléatoirement 5 points, appelés centroïdes, qui représentent le centre de chaque groupe.
- Assignation des données aux centroïdes : Chaque mail (ou objet) est ensuite assigné au centroïde le plus proche, en fonction de la distance entre l'objet et chaque centroïde.
- Mise à jour des centroïdes : Après avoir assigné tous les objets, les positions des centroïdes sont recalculées. Ce processus se fait en prenant la moyenne de tous les objets assignés à chaque centroïde.
- Répétition jusqu'à la stabilisation : Les étapes 3 et 4 sont répétées jusqu'à ce que les centroïdes ne changent plus de position de manière significative, signifiant que les groupes sont stables.
Optimisation du Tri des E-mails
Ce système simplifie et améliore la gestion des e-mails en deux étapes clés, en permettant un tri rapide et pertinent basé sur le contenu:
- Extraction des Attributs : Chaque e-mail est analysé pour en extraire des caractéristiques clés comme les mots-clés et la longueur du message, converties en vecteurs numériques pour une analyse précise.
- Classification Automatique : En utilisant l'algorithme de K-Means, les e-mails sont regroupés selon leur contenu similaire. Ainsi, des messages sur des sujets communs comme des réunions sont classés ensemble, facilitant une organisation efficace et une gestion du temps améliorée.
D’autres cas d’usage :
- Parfumerie : classification des fragrances
Situation : Une entreprise de parfumerie souhaite classer des milliers de fragrances pour développer de nouveaux parfums ou recommander des produits aux clients. Application de K-Means : Les descriptions des fragrances (notes florales, boisées, épicées, etc.) sont converties en vecteurs. K-Means est utilisé pour regrouper les parfums en fonction de leurs profils olfactifs similaires, facilitant la création de collections ou la recommandation personnalisée aux clients. - Immobilier : segmentation du marché immobilier
Situation : Une agence immobilière veut segmenter les propriétés listées pour mieux cibler les acheteurs potentiels. Application de K-Means : Les caractéristiques des propriétés (emplacement, taille, prix, etc.) sont analysées. K-Means permet de grouper les propriétés en catégories homogènes, aidant les agents à cibler des segments de marché spécifiques avec des stratégies de marketing adaptées. - Gestion de consignes de fûts de bière
Situation : Une brasserie souhaite optimiser la gestion de ses fûts de bière pour assurer un approvisionnement efficace dans différents établissements Application de K-Means : Les données sur l'utilisation et la demande des fûts dans divers établissements sont collectées. K-Means peut être utilisé pour identifier des groupes d'établissements ayant des besoins similaires en termes de volume et de fréquence de livraison, facilitant la planification logistique et la distribution.
Conclusion
L’intelligence artificielle représente une avancée révolutionnaire et continue de se développer sans cesse. À mon avis, nous en sommes toujours aux balbutiements de cette technologie novatrice qui pourrait, en s'associant à d'autres technologies existantes, déclencher une série de transformations révolutionnaires dans beaucoup de domaines différents. De plus, l'avenir de l'IA doit être façonné par une synergie entre l'innovation technologique et les principes éthiques, garantissant un progrès qui bénéficie à l'ensemble de la société.


