Understanding Artificial Intelligence models
Discover the secrets of AI models, especially LLMs like OpenAI's famous GPT. This article takes a look at how they work, how they are trained and how they adapt.

This article aims to provide an in-depth overview of AI models, focusing on LLMs (Large Language Models) such as the well-known GPT developed by OpenAI. We will examine how they work, their training process and the possibilities of adapting them to specific needs. In addition, we will discuss key concepts such as tokenization, weights and parameters. The aim is to provide a comprehensive understanding of this constantly evolving technology that is transforming the way we produce and consume information.
John Searle's Chinese bedroom
This parable, imagined by John Searle in the 1980s, describes the workings and limitations of artificial intelligence with regard to semantic understanding.
In this parable, a person with no knowledge of Chinese is locked in a room. This person is provided with a catalog of rules allowing him or her to respond to sentences in Chinese. These rules are based solely on the syntax of the sentences, and take no account of the meaning or significance of the words.

The operator in the room receives sentences written in Chinese and, by applying the rules at his disposal, produces other sentences in Chinese that constitute coherent answers. However, this person has no real understanding of the meaning of the Chinese sentences he manipulates. He or she is simply following the pre-established rules, without any real semantic understanding.
The Chinese Chamber, a parable used to challenge the idea that machines can truly understand language like humans, raises questions about the nature of artificial intelligence. It highlights the difference between symbolic information processing and deep semantic understanding, putting into perspective the ability of machines to truly understand the meaning of words and sentences.
The different types of Machine Learning models
Artificial intelligence research is constantly evolving, leading to the regular creation of new models and techniques. These advances and discoveries in the field manifest themselves through a variety of model types, each offering new approaches, different architectures or specific optimizations.
Today, there are dozens of such model types, and for an overview, here are two commonly used types:
- LLM (Large Language Model): refers to models such as GPT developed by OpenAI. Designed to ingest and generate text, they use neural networks to analyze linguistic structures and rules. Often used for tasks such as machine translation, LLMs are also used for text generation.
- CNN (Convolutional Neural Network): a model commonly used for image recognition and processing. By analyzing local relationships between pixels, they capture important image features. CNNs are enjoying great success in tasks such as image classification, object detection and facial recognition.
Tokens definition and operation
A "token" refers to an elementary unit of text used in natural language processing. It can represent a word, part of a word or even an individual character, and helps standardize the representation of text for analysis and processing by AI models. Tokenization is useful for several reasons:
- It facilitates text processing and analysis by representing words in a standardized way.
- It reduces the size of texts by dividing them into tokens, as models have a fixed memory limit for data processing.
- LLM (Language Models) are based on transformers and use mathematical operations on token representation vectors. The tokens thus enable the model to understand and generate text using these vectors.
How tokenization works
openAI's Tokenizer tool gives a quick look at how GPT "tokenizes" a sentence, here's an example:

With the 26-character phrase "Atipik will save the world", we can see that it is split into 7 pieces, i.e. 7 tokens. We can also see that several tokens include a space, which facilitates and optimizes encoding. So you don't need to use a separate token for each space between characters.

Each token can be composed of a series of letters, or even a single letter in some cases, and generally forms a word that is associated with its ID.
- will = 481
- save = 3613*
- the = 262*
- world = 995
There's no "Atipik" token, because it's not widespread enough on the Internet, so GPT didn't come across it often enough when learning it. The model will therefore not know it as a single entity, but rather as three combinations of two letters each: "At", "ip", "ik". It then divides the word into more common sub-units, called subword tokens, to represent it. This approach enables the model to better handle rare or unknown words by breaking them down into more familiar parts.
The numbering of tokens is based on their relative position in the training set. That is, a common word in English, such as "the", may receive a lower token ID than another simply because it appears more frequently in the training set.
Is ChatGPT multilingual?
ChatGPT has been trained on a large number of English texts. However, it is also capable of handling other languages, including French. When you use a tokenizer with GPT to split text into tokens, it will find tokens associated with words in French as well as English.
Some sources claim that since GPT has been trained with English text, it won't find associated tokens for French words. This may explain why its relevance is higher in some cases in English.
Please note that Chatgpt has no specific information on its own internal technical details, as this information is not publicly available. (And he's the one who says so).
Despite the fact that the French version of "Atipik va sauver le monde" is one character shorter than the English version, it is split into 10 tokens, compared with 7 in English.

With the exception of two-letter combinations, the words "save" and "world" are not considered as a single token, as was the case for "save" and "world" in English.
.png)
In the example "C'est incroyable", we can see the tokens "est", "inc", "roy" and "able". Whereas "incredible" exists as a single token.
It's important to note that the tokenization process may vary depending on the specific tokenizer used. Different tokenizers may adopt different decomposition strategies.
Weights and parameters
The quantity of parameters in an AI refers to the number of adjustable variables or weights used in the machine learning model. These parameters enable the AI to make decisions and learn from the data.
To draw an analogy with the human brain, parameters can be thought of as the connections between neurons. In the brain, neurons are interconnected and communicate with each other to process information. Each connection represents a specific interaction between two neurons, and it is this complex structure that enables the brain to perform a variety of tasks.
Similarly, in AI, parameters determine how the different parts of the model interact and transmit information to each other. These parameters are adjusted during the learning phase to enable the AI to perform specific predictions and tasks.
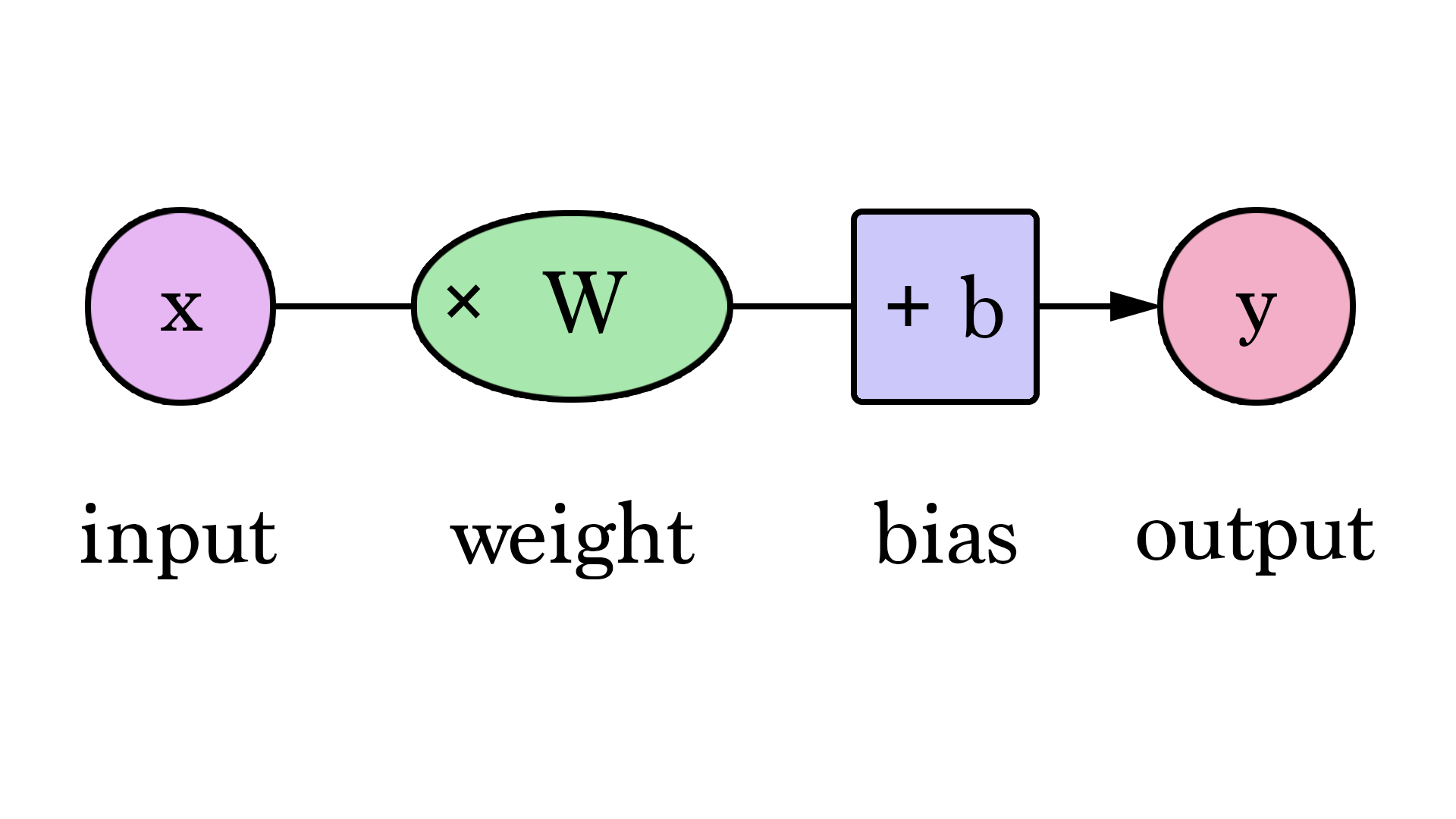
They are used to adjust the algorithm's behavior. For example, in a neural network model, each connection between neurons has an associated weight, which determines the relative importance of that connection.
During the learning phase, these parameters are adjusted by the learning algorithm to minimize the discrepancy between model predictions and expected results. This process is called gradient backpropagation (remember this term to shine in society ✨).
To give an analogy with the human brain, we can think of parameters as factors that influence the strength of synaptic connections between neurons. When you learn something new, the synaptic connections in your brain strengthen or change to reflect this new information.
Bias is simply the difference between prediction and expected value. Bias is the difference between the result of the function and the expected result.
How does AI training work?
Training an LLM model, which is a model that predicts the next word in a text, is fairly straightforward. There's no need for formatting, a sentence taken from a book or website is enough.

The sentence can be cut at any point and given to the model to practice guessing the next word. In this way, a single sentence can be used to create a multitude of examples by cutting it at different points.
As a result, large quantities of data from a variety of sources can be fed into the model, without the need to involve a human in the process.
This table shows the types of data used to train the GPT-3 model.
A benchmark between several hundred models was carried out by lifearchitect.ai, and can be accessed via this link.
How to refine Machine Learning models
To refine the model, or specialize it in a particular domain, one possibility is to have it read a JSON file a multitude of times, in le format SQuAd:

There are originally 2 types of SQuAD format:
- SQuAD 1.1: in this version, each data example comprises a context and a question associated with that context. The model must predict a text response in the given context. Like the example above.
- SQuAD 2.0: this version adds an additional element to the data format. Each example can also contain an "impossible " response. This means that some questions may not have a valid answer in context. This change has been introduced to encourage models to take into account the possibility that a question may not have a correct answer.
There are other variants of the SQuAD format, specific to the model to be refined.
The model will read the data a multitude of times, adjusting its weights on each pass, in order to produce an answer as close as possible to the one expected for a given question (the bias as seen above).
The tool on the repo LLaMA-LoRA Tuner gives a quick overview of how to refine an LLM model.
Conclusion
The subject is both fascinating and frustrating due to its constant and rapid evolution. A lot of effort is required to closely follow this lively and captivating technology. This article itself will surely become outdated quickly due to the fervor surrounding this tool that is revolutionizing the internet.
The journey into the intricacies of artificial intelligence, particularly through LLMs such as GPT, raises fundamental questions about the ability of these systems to grasp the true meaning behind the words they generate. As we ponder the possibility of AI transcending mere imitation of intelligence to achieve genuine understanding, we open the door to an even deeper exploration of this technology. It is with this in mind that we invite you to discover our following article: "AI and vectors, when your data makes sense." This new section delves into the workings of vectors and vector databases, cornerstone elements that allow artificial intelligences to decipher and interpret the nuances of information.


